Virtual Memory
Ostep Virtual Memory
The Abstraction: Address Space
Multiprogramming and Time sharing
- 為了避免process之間的互相等待,因此從signalprogramming進步到multiprogramming,但在效能提升的同時,如和避免process之間互相干擾成了另一個問題
Address Space
- Address space是process的虛擬記憶體,每個process都具備自己的address space
- process的address space包含運行程序的所有記憶體狀態,比如code必須在記憶體中,因為他們在因為他們在address space裡
- 當程式運行時利用stack保存函數調用訊息,分配空間給局部變量
- 利用heap管理動態分配的以及用戶管理的記憶體
虛擬Memory的目標
- transparency: process感知不到memory被虛擬化的事實,反而認為自己擁有自己的private physical memory
- efficiency: os追求虛擬化盡可能的effiecnt,包括在時間和空間上.在實現高效率虛擬memory時,os不得不依靠硬體
- protection: os應該確保process受到保護不會受到其他process影響,os本身也不會受到任何process影響.當一個prcess執行load,store或指令提取時,不應該用任何方式訪問或影響其他prcess以及os本身的memory
你看到所有地址都不是真的
- 使用C語言打應出來的地址是虛擬地址,並且將由os轉換成物理地址
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[]) {
printf("location of code: %p\n", (void *)main);
printf("location of heap: %p\n", (void *)malloc(1));
int x = 3;
printf("location of stack: %p\n", (void *)&x);
}Mechanisms: Address Translation
- 實現CPU虛擬化時,我們遵循的準則被稱為Limited Direct Execution (LDE)
- LDE原則是os盡量不干擾CPU執行process,只有在關鍵時才及時介入(interposing)來保持對硬體得控制
- 利用基於硬體的地址轉換(hardware-based address translation)又稱address translation 來保證高效靈活的虛擬化
- 使用address translation,硬體對每次memory訪問進行處理都將指令中的victual address轉為十集的physical address來實現受限執行
- 因此每次memory訪問時,硬體都會進行address translation,將應用程式的memory引用重定位到memory實際位置
Example
- 編寫一段C語言程式碼
int main() {
int x;
x = x + 3;
}- 使用otool來反編譯程式成ASM code
0000000100003f90 ldr w8, [sp, #0xc] # 載入x變量
0000000100003f94 add w8, w8, #0x3 # 將x變量加3
0000000100003f98 str w8, [sp, #0xc] # 將結果存回x變量使用匯編的角度來看
- 從地址3f90獲得指令
- 執行指令(從地址0xc載入數據)
- 從地址3f94獲得指令
- 執行指令(沒有memory訪問)
- 從地址3f98獲得指令
- 執行指令(將結果存回0xc地址)
使用程式角度
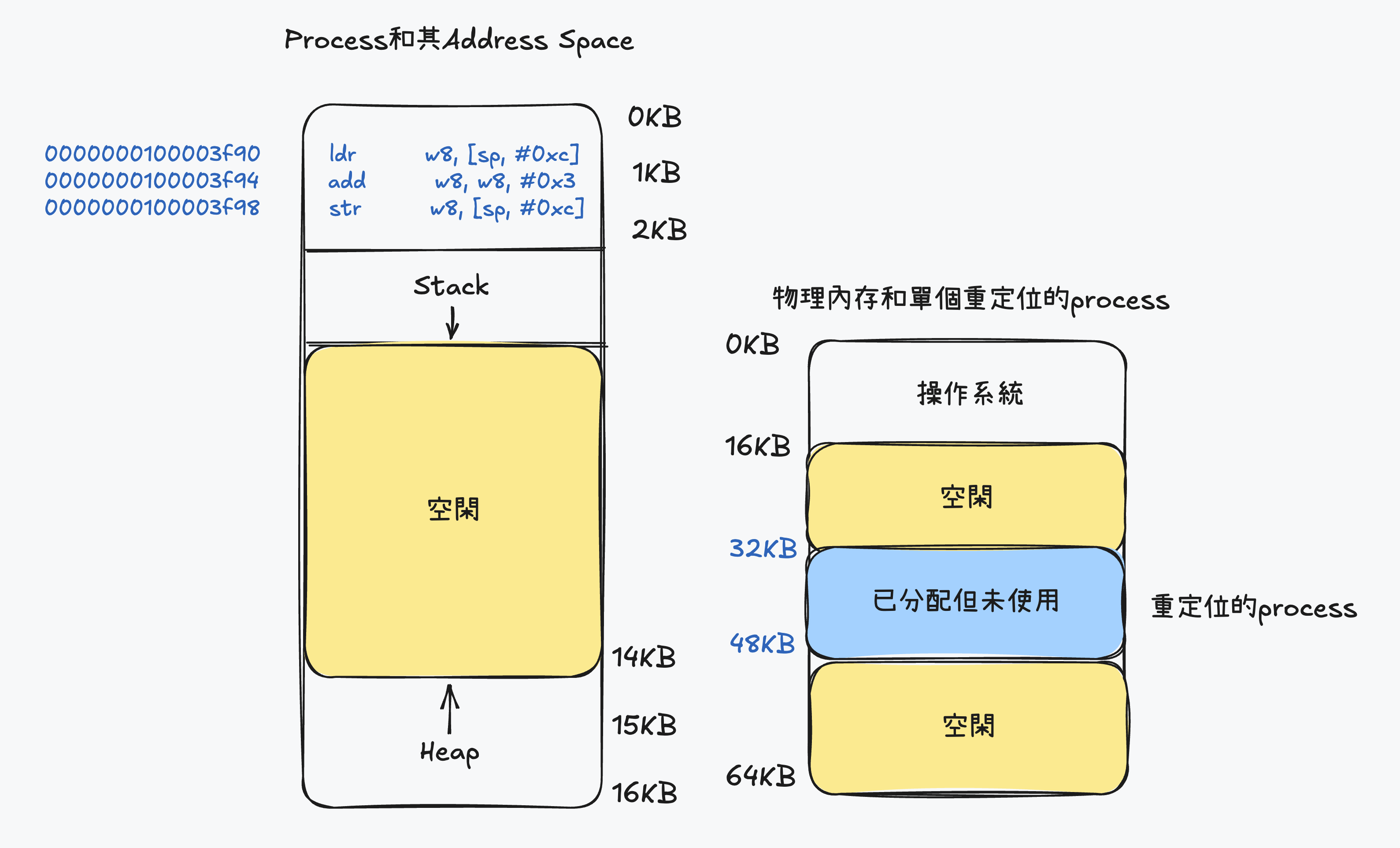
- 他的address space從0開始到16KB結束,所有的memory引用都在這範圍內
- 然後虛擬memory來說,os希望將這些位址放在物理memory的不同地方,不一定從地址0開始,那我們該如何重定向這個process以及對該process保持transparent
- 底下圖片說明process的address space被放入物理memory後可能的樣子,從圖可以看到操作系統第一塊物理memory留給自己,並將上述地址空間重店味道從32KB開始的物理memory地址,剩下的兩塊memory空閒
Dynamic Address Translation
- CPU需要兩個硬體Register分別是base register和bound register(也稱為limit register)
- base register: os決定process在其裡memory中的實際address,並將起始的address記錄在base register中
- bound register: os決定process在其裡memory中的結束address,並將結束的address記錄在bound register中
- 當CPU訪問memory時,會將虛擬地址與base register和bound register進行比較
- 如果虛擬地址小於base register或大於bound register,則會報錯
- 如果虛擬地址在base register和bound register之間,則將虛擬地址加上base register的值來獲得物理地址
- 由上述可以得出一個公式
Bound Register作用
- bound register是為了確保process不會超過其address space的範圍,如果process試圖訪問超出其address space的memory,則會報錯
- 進而隔離當前process和其他process,確保process之間不會互相干擾

- process中使用德的memory引用都是virtual address,硬體接下來將vitrual address加上base register的值來獲得physical address
- 底下簡化先前的asm code中指令的位址
- 簡化0000000100003f90成128(數字代替表達,不考慮轉換以及值是否正確)
128 ldr w8, [sp, #0xc] # 載入x變量流程
- 當PC首先被設置為128後
- 硬體需要獲得這條指令時,先將這個值(128)加上base register的值32KB(32768)來獲得實際的物理位址(32896)
- process從virtual address 15KB的加載,處理器同樣需樣virtual address 15KB加上base register的值32KB(32768)來獲得物理位址(48768)
- 有了物理位址後,處理器可以從物理memory中讀取數據
- 將虛擬地址轉換為物理地址的過程稱為address translation技術ㄓ,而當這種address translation在運行時發生,並且我們甚至可以在process運行後改變其address space,這種技術被稱為dynamic address translation
Dynamic Address Translation要求
- 硬體必須提供base and bound registers,因此每個CPU的Memory Management Unit (MMU)都必須額外擁有這兩個register
- 硬體提供一些privileged指令,只有在kernel模式下指行,其作用為修改base register和bound register的值
- 當用戶嘗試非法訪問memory時(越界訪問),CPU必須能夠產生異常(exception)並安排os的exception handler來處理這個問題
| 硬體要求 | 解釋 |
|---|---|
| 特權模式 | 需要,以防用戶模式的process執行特權操作 |
| base/bound register | 每個CPU需要一對register來支持地址轉換和bound檢查 |
| 能夠轉換virtual address並檢查是否越界 | 電路完成轉換和檢查bound |
| 優改base/bound register的特權指令 | 再讓用戶程式運行之前,os必須能夠設定值 |
| 註冊異常處理的特權指令 | os必須能夠告訴硬體,當異常發生時執行那些程式 |
| 觸發異常 | 如果process試圖使用特權指令或越界訪聞 |
OS: The New Problem
- 為了支持dynamic address tanslation,硬體支持和操作系統管理結合在一起,實現了一個簡單的虛擬內存系統,因此在關鍵時刻os需要介入,已實現base bound方式的虛擬Memory
- 當process創建時,os必須找到足夠的memory address,而整個操作都會圍繞在Free list上
- 可以把整個物理Memory想像成一組抽屜,標記了空閑或以使用,當new process創建時ㄝos檢索這一個抽屜,為新的address space找到位址,並標記成已被使用
- 當process終止時,os也必須做一些工作,回收他的所有Memory,給其他process使用,當process終止時,os將會把這些Memory放回空閑列表,並根據需要清除相關的數據結構
- 在context switch時,os必須執行一些額外的工作,由於每個CPU都只有一組base and bound register,因此os必須保存和恢復base和bound register
- 當process停止時(即終止運行),os可以改變其地址空間的物理位置
- 要移動process的address space步驟
- os讓process停止運行
- 將address space拷貝到新的位置
- 更新保存的base register(在process結構中)
- 指向新位置
- 當process恢復執行時,其(新)base register就會被恢復,顯然他的指令和數據都在新的Memory位址
- os必須提供exception handler,或要一些function,當process越界訪問Memory時,CPU會觸發異常,os必須要能夠終止這些process
| 操作系統的要求 | 解釋 |
|---|---|
| 內存管理 | 需要為新process分配Memory |
| 從終止的process回收Memory | |
| 一般通過free list來管理Memory | |
| base bound 管理 | 必須在context switch時正確設置base和bound register |
| 異常處理 | 當異常發生時執行的程式,可能的動作是終止犯錯的process |
補充: FreeList
基於時間線展示硬體和os的互動
Boot
| OS @boot (kernel mode) | Hardwarre |
|---|---|
| initialize trap table | |
| remember address of... | |
| system call handler | |
| timer handler | |
| illegal mem-access handler | |
| illegal instruction handler | |
| Run main() | |
| Execute return from main | |
| start interrupt timer | |
| start timer;interrupt after | |
| initialize process table | |
| initialize free list |
Run
| OS @run (kernel mode) | Hardwarre | Program (user mode) |
|---|---|---|
| To start processA: | ||
| 1. allocate entry in process table | ||
| 2. alloc memory for process | ||
| 3. set base and bound registers | ||
| 4. return-from-trap (into A) | ||
| restore registers of A move to user mode jump to A's(initial) PC | ||
| Process A runs Fetch instruction | ||
| translate virtual address perform fetch | ||
| Execute instruction | ||
| if explicit load sotre | ||
| 1. ensure address is legal | ||
| 2. translate virtual address | ||
| 3.perform load and store | ||
| Process A runs | ||
| Timer interrupt | ||
| move to kernel mode | ||
| jump to handler | ||
| Hnadle timer | ||
| 1. decide: stop A, run B | ||
| 2. call switch() routine | ||
| 3. save register(A) to process-struct(A) (include base and bound registrer) | ||
| 4. restore register(B) from process-struct(B) (include base and bound registrer) | ||
| 5. return-from-trap (into B) | ||
| restore register of B | ||
| move to user mode | ||
| jump to B's PC | ||
| Process B runs Execute bad load | ||
| Load is out-of-bounds | ||
| move to kernel mode | ||
| jump to trap handler | ||
| Handle the trap | ||
| decide to kill process B | ||
| deallocate B's memory | ||
| free B's entry in process table |
目前問題
- 簡單的Dynamic Address translation能夠支持Process transparent但還有問題無法解決
- 重定位process使用了從 到 的物理地址,但由於process的stack和heap並不是很大,導致這塊Memory中大量的空間被浪費
- 這種浪費稱為intrenal fragmentation
internal fragmentation
- 指的是已經分配的Memory單元內部有未使用的空間(即fragmentation).造成了浪費,
- 因為這些fragmentation無法被其他process使用(不足其他process的需求)
- 在我們當前的方式中,即使有足夠的物理Memory容納更多process,但我們目前要求將adress spoace放在固定大小的抽屜,因此出現了internal fragmentation
Segmentation
- 目前的情況都是將所有的process載入到Memory中,並且使用base/bound register來讓os將不同的process進行address translation到不同的physical address,但這樣會發現在stack和heap間存在很大的空閑區塊

Segmentation 范化的base/bound
- 在MMU中引入不只base/bound register,而是給address space內的每個segment一對,一個segment只是address space中的連續定長區域,典型的segment有3個部分
- code
- stack
- heap
- segment讓os將不同的segment放到不同的physical address,從而避免了虛擬address space中未使用但佔用physical memory的問題
| segment | base | bound |
|---|---|---|
| code | 32KB | 2KB |
| heap | 34KB | 2KB |
| stack | 28KB | 2KB |
-
假設現在引用virtual address為100的地址,MMU將base加上偏移量得到實際的physical address , 然後再檢查該地址是否在bound內(這邊的地址指的不是實際physical address,而是vitrualaddress 的地址) , 發現再bound內部後就發起調用
-
再看到圖1的範例,假設現在要引用的是heap的地址,假設直接將4200加上stack的base 34KB的話會是錯的,因為4200的基底是從4KB(4096)開始,因此應該是 , 然後再檢查該地址是否在bound內,確認在bound內後再將 得到實際的physical address
-
當我們試圖訪問超過bound的address時,就會發生segmentation violation 或是 segmentation fault
怎麼知道調用的是那個Segment

- 由圖中可以知道前兩位代表的是告hardware説調用的是哪一個段(stack,heap,code),剩下的12位則是偏移量
- 因此先使用前兩位找到相對應的segment後再使用偏移量+基底address就可以獲得實際的物理位址
- 現在可以將上述所做轉換成程式碼的形式,也因為偏移量簡化了對bound的判斷,因此只需要檢查偏移量是否小於bound而非大於bound的非法地址
#define SEG_MASK 0x3000
#define SEG_SHIFT 12
#define OFFSET_MASK 0xFFFF
// get top 2 bits of 14-bit
Segment = (VirtualAddress & SEG_MASK) >> SEG_SHIFT
// get offset
Offset = VirtuaalAddress & OFFSET_MASK
if (Offset >= Bounds[Segment])
RaiseException(PROTECETION_FAULT)
else
PhysAddr = Base[Segment] + Offset
Register = AccessMemory(PhysAddr)- 這邊只使用兩個段是因為,假設使用3個段表示的話,有可能會造成其中一個被浪費,因此有些系統會將heap和stack當成一個段,然後用一bit來做標示
- 在implicit方式中,硬體功過address產生的方式來確定段
- 例如: 如果地址由pc產生,即為指令獲取,則位址在code段, 假設基於stack或base指針則一定在stack段,其他地址在heap段
How about Stack
- 在上圖中可以看到stack被重定位到28KB的地方,但和其他不同的地方在於stack是反向增長的,也就是始於28KB增長到26KB,相對應的虛擬地址也是從16KB到14KB
- 因此硬體需要額外已1bit來區分是否為反相增長(1代表正向,0代表反向)
| segment | base | bound | reverse |
|---|---|---|---|
| code | 32KB | 2KB | 1 |
| heap | 34KB | 2KB | 1 |
| stack | 28KB | 2KB | 0 |
- 因為反向的緣故,在計算address transtaltion時會有所不同
- 假設現在要訪問的是15KB的虛擬地址,對應到的物理地址為27KB
1, 先將15KB轉換成2進制形式 11 1100 0000 0000,利用前兩位來指定段,並且計算出偏移量為3KB 2. 為了得到正確的偏移量,因此要將現在的偏移量減去最大的段地址(即為bound的上界地址)
- 此時再將偏移量加上base address得到實際的physical address
- 進行bound檢查,確保偏移量的 絕對值 小於sagment的大小
Support Shared
- 為了節省Memory,有時會在address space之間共向segment是有用的行為,因此硬體會需要新增protecetion bit來標示是否能夠對segment進行RW
- 將code segment標示為只讀時,可以讓他被多個process共享但不會破壞process 間的隔離
| segment | base | bound | reverse | protect |
|---|---|---|---|---|
| code | 32KB | 2KB | 1 | Read-Excute |
| heap | 34KB | 2KB | 1 | Read-Write |
| stack | 28KB | 2KB | 0 | Read-Write |
- 有了protection bit後前面虛擬地址是否越界外,還需要檢查特定的訪問是否允許,如果從事非法訪問hard會拋出異常並且讓os來handle這些error
操作系統支持
- 現在當系統運行時,address space會被不同的segment重定位到physical memory中,相比於之前使用base/bound的方法節省了不少的physical memory
- 具體來說 stack和heap不需要再分配physical memory,讓我們能將更多的address space放入 physical memory
遇到的問題
- os在進行Context switch 時該做些什麼
- 各個segment register中的內容必須保存和恢復,因為每個process都有自己獨立的vritual address space, 因此os必須在process運行前確保被正確設置
- physical address 中充滿了許多free space的小洞,這些洞很難再分配給新的segment或是擴充原有的segment,這類的問題被稱為(external fragmentation)
- 第一種解法是compact physical memory
- os 將所有的process終止後,將數據複製到連續的memory區域中,並且改變他們的segment register內的值,指向新的物理地址,從而獲得足夠大的連續空間
- 但這樣造成的問題是成本很高,因為copy segment是memory intensive(密集),因此會佔用大量的processor(處理器)時間
- 第二種解法是利用 free-space management算法,試圖保留較大的memory區塊來進行分配
Page
-
os 有兩種方法管理和解決空間問題
- 分片(segment),就像 virtual memory 中管理,但將空間切成不同長度的分片後空間會碎片化(framented),導致時間越長越難分配
- 分頁,和分片不同的是分頁不是將一個process的address space分割成不同長度的logic段,而是把physical memory看成定長曹塊的陣列(page frame)
- 每個page frame包含一個virtual memory page
-
下圖是一個關於page的簡單範例,左邊的 virtual memory而右邊是對應到的 physical memory
- 可以看到改進了原先使用segment的靈活性,通過完善分頁方法可以有效提供address space,不管process如何使用address space,並且也提供了 free list管理的簡單性
- os希望將64 byte的小address space放到8page的physical address space中只需要從free list找到4個空閑就可以
- 可以看到改進了原先使用segment的靈活性,通過完善分頁方法可以有效提供address space,不管process如何使用address space,並且也提供了 free list管理的簡單性


- 為了記錄address space中每個virtual page放在physical memory中的位置, os 會為每個process保存名為page table的數據結,主要存放為virtual page 的address translatiion
- 使用右邊的圖當作範例, page table會有以下4個條目
translation
- 現在要從virtual memory找到對應的physical memory
- 假設我們擁有64byte的process正在訪問memory
movl <virtual address>, %eax-
為了translate該過程生成的virtual address,必須將 virtual address分成兩個組件
- virtual page number, VPN
- page中的偏移量, offset
-
從剛剛virtual memory中的圖可以知道將64byte空間分成4個page,因此每個page為16byte
- 然後virtual address space總共為64byte,因此地址總共需要6位
- 此時就可以將page切塊
- 從剛剛得知一個page的大小為16Byte,因此可以知道Offset大小
- page大小為16byte位於64Byte中,因此可以選擇4個page,VPN做的就是選取這件事

Example
- 假設尋找virtual address為21
- 先將21轉為2進制
- 依照前面的算法得知
- VPN在第一頁所在的physical page (01)
- 而Offset則為(0101)
- 找到physical page中對應的PFN(由上圖得知在第7個frame),因此PFN(有時也稱PPN)為7(111)
- Offset不變
- 因此找到對應的physical address 為
paging 很慢
- 一樣使用movl模擬分頁並循找原因
movl 21, %eax- 現在只在乎對21的顯示引用,要先將21轉換成對應的physical address,但在從對應的pphysical address前,必須先從process的page中提取適當的項進行轉換
- 此時將 VPNMASK 設定為 (原因為VPN切割後只有2位)
- SHIFT為offset的位元數(4)
- 為了要獲得正在運行的process中page的位址,需要假設一個page-table base register包含page起始位址的physical address
VPN = (VirtuaalAddress & VPNMASK) >> SHIFT;
PTEADDR = PageTableBaseRegister + (VPN * sizeof(PTE));- 找到VPN後將該值作為page-table base register指向PTE數組的index
- 一但知道這個物理地址後,hardware就可以從memory中獲得PTE並且提取PFN,並將來自Virtual address的offset進行計算,形成最後的physical address
- 可以想像PFN被SHIFT左移,然後和偏移量進行計算形成最終地址
VPN = (VirtuaalAddress & VPNMASK) >> SHIFT;
PTEADDR = PageTableBaseRegister + (VPN * sizeof(PTE));
PTE = AccessMemory(PTEADDR);
if(PTE.valid == False)
RaiseException(SEGMENTATION_FAULT);
else if(CanAccess(PTE.protectBits) == FALSE)
RaiseException(SEGMENTATION_FAULT);
else
offset = VirtuaalAddress & OffsetMask;
PhysAddr = (PFN << SHIFT) | Offset;
Register = AccessMemory(PhysAddr);Memory Trace
- 假設今天有一個C code
int array[1000];
// ...
for(int i=0;i<1000;i++)
array[i] = 0;- 將它轉換成asm code後
0x1024 movl $0x0, (%edi,%eax,4)
0x1028 incl %eax
0x102c cmpl $0x03e8,%eax
0x1030 jne 0x1024- 假設有一張線性表(array)則可以由此推斷出在此數組中VPN對應的PFN
- mov 則會有一個顯示的memory 引用,這會先增加另一個page table訪問(將數組vritual address轉換成正確的physical address)

- 假設現在超過圖中的5次訪問
- 當找到超過當前VPN時會進行換頁查找
- 而會新訪問incstruction memory, data memory(array), page table memory
TLB
- 現在的paging之所以慢是因為將memory address space切分成大量固定大小的page,並且需要記錄mapping的訓息(virtual -> physical)
- 因為這些訊息一般存在physical memory中,所以在translation virtual memory時,page需要一次額外的memory access
- 每次的fetch instruction, load, store都需要額外讀一次memory才能得到translation訊息
使用Cache解決
- 增加translation-lookaside buffer(TLB)儲存頻繁發生的virtual address to physical address的hardware cache
- 因此也稱為address-translatiion cache
- 對每次memory access, hardware先檢查TLB內的訊息,如果有可以直接完成mapping而不用訪問page table
TLB基本算法
VPN = (VirtuaalAddress & VPNMASK) >> SHIFT;
(Success,TlbEntry) = TLB_Lookup(VPN);
if(Success == true)
if(CanAccess(TlbEntry.ProtectBits) == True)
offset = VirtuaalAddress & OffsetMask;
PhysAddr = (TlbEntry.PFN << SHIFT) | Offset;
Register = AccessMemory(PhysAddr);
else
RaiseException(SEGMENTATION_FAULT);
else
PTEAddr = PTBR + (VPN * sizeof(PTE));
PTE = AccessMemory(PTEADDR);
if(PTE.valid == False)
RaiseException(SEGMENTATION_FAULT);
else if(CanAccess(PTE.protectBits) == FALSE)
RaiseException(SEGMENTATION_FAULT);
else
TLB_Insert(VPN,PTE.PFN,PTE.ProtectBits);
RetryInstruction();文字流程如下
- 從Virtual address中提取VPN
- 檢查TLB內是否有該VPN的轉換地址
- 假設命中成功,則從相關的TLB取出PFN後與原來的virtual address中的Offset組合形成Physical address,並訪問memory
- 如果沒有命中,hardware訪問page table來尋找PTE
- 假設該PTE可以訪問
- 將新的translation 訊息插入TLB
- 重新執行一次指令(讓該TLB hit然後訪問Memory以避免什麼都沒發生)
- 因為訪問page table需要額外的memory access因此造成較大的性能開銷,因此我們會希望盡量避免TLB miss
Access array
- 一開始先訪問a[0],TLB miss後將VPN=06的translation information都放入cahce
- 接下來訪問a[1],就可以直接TLB hit然後進行轉換
- 因此最後總共會有7次的TLB hit,3次的TLB miss, hit rate為70%

- 因此我們知道page的大小會影響結果,對於像array這種密集訪問的memory會獲得極好的性能
- TLB的成功依賴於時間局部性(temporal locality)和空間局部性(spatial locality),只要某個程式表性出這種局部性,就可以獲得較高的命中率
Use Caching When Possible
- the idea behind hardware caches is to take advantage of locality in instruction and data references
- 時間局部性(temporal locality)
- 指的是最近訪問過的元素在短時間內很有可能再被訪問
- 空間局部性(spatial locality)
- 指的是當成是訪問memory address為x時,在短時間內很有可能再訪問和x相鄰的memory
TLB瓶緊
- Cache 並不是越大越好,會因為物理限制而受到影響 (Memory Hierarchy將影響混合其他儲存硬體來避免物理限制)
- TLB很容易成為CPU流水線的性能瓶緊,尤其是當存在pyhsical-indexed cache,address translation 必須發生在access該cache前,這會導致動作變慢
- 使用virtual address直接訪問physical address 從而避免當發生cache hit時昂貴的address translation,像這種virtually-indexed cache解決了性能問題,但也為hardware design帶來新問題
Who Handles The TLB Miss
- 硬體
- 硬體需要知道page table在memory中的確切位址(透過page-tabe base register),以及page table確切的格式
- 因此發生miss的時候會遍歷整個page table,找到正確的page,取出translation information後更新TLB
- 軟體
-
使用RISC來處裡TLB Miss
- 當TLB Miss後硬體會拋出一個異常,將會暫停當前的instruction steam,並且將提升至kernal mode後跳轉至trap handler
- 這個trap handler用來處理TLB miss,當他運行時會查找page table中的translation information,然後使用 privileged instruction來更新TLB
-
軟體中的trap handler不同於之前os的trap handler
- 會將PC重置到導致TLB miss的instruction,然後再次執行一次,這次就會TLB hit
- 處裡TLB miss時為了必免處理程式陷入無線回圈的狀態
- 把TLB miss中trap handler直接放到physical memory中,讓一發生miss就直接強制觸發
- 在TLB中設定保留項,紀錄永久有效的translation address,並將一些槽塊給TLB miss處理程式,讓這些被wired的translation address永遠發生TLB hit
-
相較於硬體處理方式,軟體具備的主要優勢
- 靈活性: 可以用任意數據結構實現page table
- 簡單性: hardware只需要拋出異常後,剩下交給TLB miss處裡程式即可
Context switch 對 TLB 的處理
- 在context switch時假設現在有P1,P2
- P1 VPN10映射到PFN100
- P2 VPN10映射到PFN170
| VPN | PFN | Valid | Protect |
|---|---|---|---|
| 10 | 100 | 1 | rwx |
| - | - | 0 | - |
| 10 | 170 | 1 | rwx |
| - | - | 0 | - |
- 此時會發現當訪問VPN 10的TLB時會發現不知道要映射到的PFN是100還是170
解決方法
- 清空(flush) TLB
-
flush 操作就是將全部的Valid設為0,本質上就是清空TLB
- 軟件:
- 發生上下文切換時,通過一條 privileged instruction完成
- 硬體:
- 可以在可以在page table base register 內容發生變化時清空TLB (當context switch時,os必須改變PTBR的值)
- 軟件:
-
當context switch時因為會清空TLB,如果頻繁切換process會造成大量開銷,因為會導致訪問數據或code page時都會觸發TLB Miss
- 增加硬體支持
- 在TLB中增加Address Space Identifier (ASID),可以將ASID當成Process Identifier(PID),但通常會比一般的PID位數少(PID一般32位元,ASDI一般8位元)
| VPN | PFN | Valid | Protect | ASID |
|---|---|---|---|---|
| 10 | 100 | 1 | rwx | 1 |
| - | - | 0 | - | - |
| 10 | 170 | 1 | rwx | 2 |
| - | - | 0 | - | - |
- 有了ASID時TLB可以同時緩存不同process的address space,不會造成任何衝突
- 硬體也需要知道當前是哪個process正在進行,以便進行address translation
- 因此當發生context switch時,必須將某個 privileged register 設置為當前process的ASID
另一種情況
- 假設現在將兩個不同的VPN映射到相同的PFN
| VPN | PFN | Valid | Protect | ASID |
|---|---|---|---|---|
| 10 | 100 | 1 | rwx | 1 |
| - | - | 0 | - | - |
| 50 | 100 | 1 | rwx | 2 |
| - | - | 0 | - | - |
- 這時可以用share page table的方法的方法來減少physical page的使用,從而減少了memory開銷
TLB 替換策略
- LRU(least-recently-used)
- 應用memory引用stream的局部性,將最近最少使用的項當作最先踢掉的項
- Random
-
隨機選擇一項換出去
-
假設有一個程式循環訪問n+1個頁,但TLB只能存放n個頁,這時如果使用LRU就會顯得開銷變大(因為LRU會去訪問memory),因此應該使用random解決
RAM不總是RAM(Culler 定律)
- Random-Access Memory初衷是為了讓訪問任何一個部分都一樣快,但結果其實必然.當訪問的random memory address並沒有被緩存在TLB時,可能導致嚴重的性能開銷
Paging: Smaller Tables
- 線性表非常的大,假設有一個32位元 address space, 4KB的page且每一個page entry都為4byte,page table大小大約4MB
- 通常一個process都會有一個page table,因此造成Memory非常大的負擔
解決方法1 更大的page
- 現在將page變更大來儲存更多的內容,原先的page entry為 個 entry
- page table 大小為
- 假設我們將page變成16KB,現在entry數量變為 個entry
- 重新計算後總共的page table為
- 但大memory table會造成internal fragmentation 問題(因為浪費在分配單元內部),應用程式會分配page,但每次都只會用其中的一小部分,導致這些memory很快就會充滿這些大page
解決方法2 混合使用 Segment 和 Paging
- 和一般Segment不同的在於原先Segment中的 base/bound register指向的是Segment本身,混合使用時則時
- Base register: 該Segment的page table 在physical memory中的address
- Bound register: 該page table的結尾(即有多少Valid page)
- 混合方法的vritual memory如下,address space前兩位

| sign | segment |
|---|---|
| 00 | 未使用segement |
| 01 | code segment |
| 10 | heap segment |
| 11 | stack segment |
- 現在每個segment的base register都會包含該segment的page table physical address,因此每個process都會有3個與其關聯的page(code,heap,stack)
- 當發生context switch 時必須更改這些base register,以反應新運行process的page table位址
TLB Miss
- 當發生TLB Miss的時候,hardware使用SN(分段位)來確定要使用的base/bound pair,然後將其physical address與VPN結合,形成PTE(page table entry)的地址
SN = (VirtualAddress & SEG_MASK) >> SN_SHIFT;
VPN = (VirtuaalAddress & VPN_MASK) >> VPN_SHIFT;
AddressOfPTE = Base[SN] + (VPN * sizeof(PTE));- 因為每個segment都有base/bound register,且保存了segment的最大valid page,因此heap和stack間未分配的page不再佔用page table的空間(將valid標示為0)
- 但遺憾的是因為使用segment因此失去了靈活性,而且有一個大而稀疏的heap任然導致大量page table的浪費
Multi-level Page Tables
- Multi-level page table將線性page table轉換成類似tree的結構,而不依賴segment且將page table中的無效區域捨去而不是放在memory中
- 核心思想是使用page directory來追蹤page table中的page是否有效
簡單二級表
- 從下圖可以發現 page directory 具備多個Page Directory Entries(PDE) 用來存放Page table
- PDE至少擁有valid bit和oage frame number (PFN)
| PDE | 含義 | PTE |
|---|---|---|
| 1 | 透過PFN指向的page table至少有一page是有效的 | 1 |
| 0 | PDE其餘部分都沒有意義 | 0(無意義) |
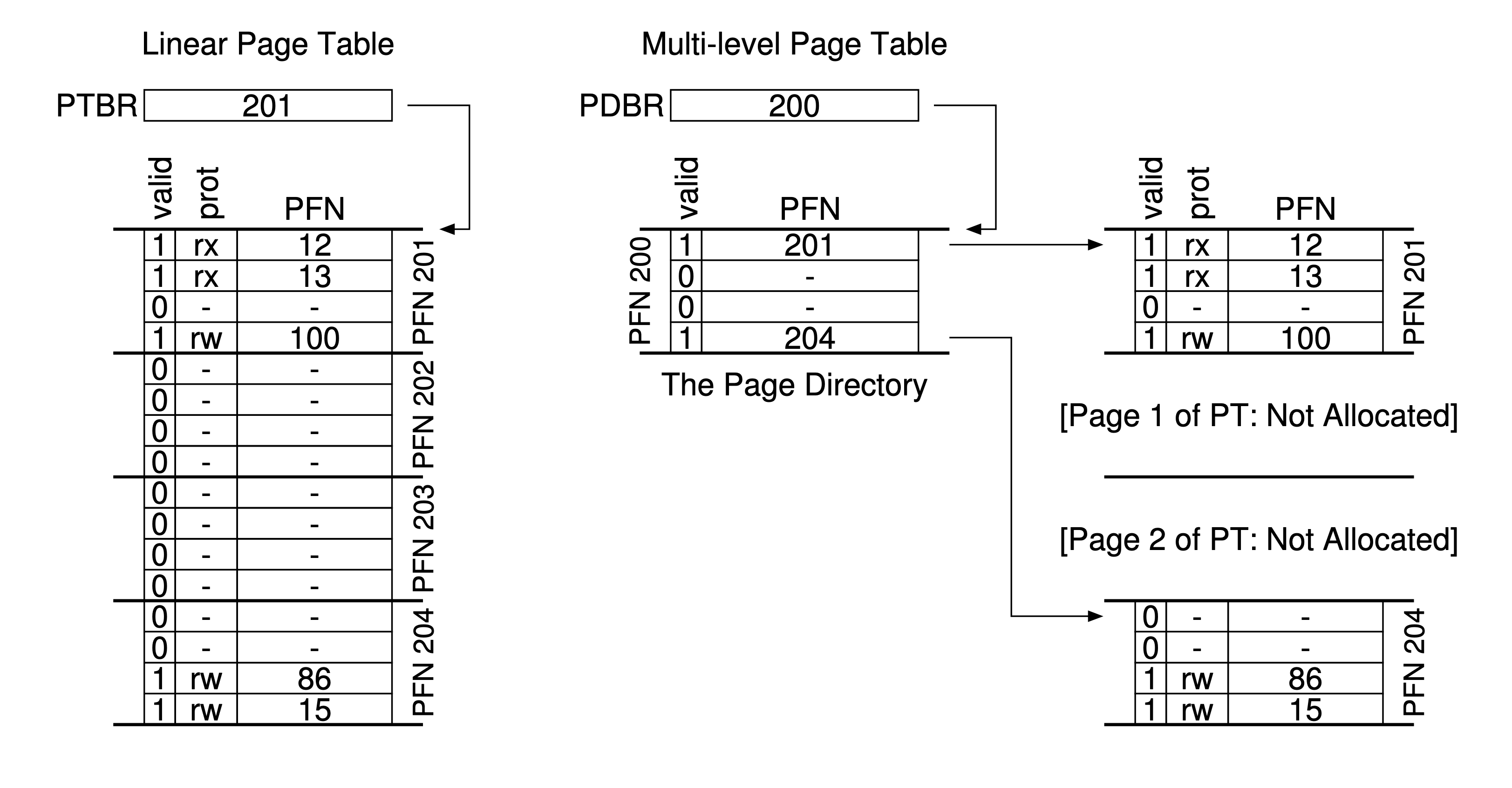
-
multi-level table only allocates page-table space in proportion(部分) to the amount of address space you are using
-
因此通常緊湊且支持稀疏的address space
-
在Mulit-level page table中page table的每個部分都可以放入page directory中,因此比非分頁線性page table更好管理
- 非分頁線性page table 需要按照VPN indexed 的 PTE array找到,對於一個相對大的page table,要找到能存放他的連續空閑physical address是相對困難
- multi-level page table使用一個中間層(level of indirection)即為page directory管理page table的各個部分,由於間接的方式,能將page table放在memory的任何地方
缺點
- Multi-Level page table發生TLB Miss的時候,會需要訪問兩次memory才可以從Page table中或正確的translation address(一次page directory,一次PTE本身)
- 因此Multi-level page table 為一種time-space trad-off,以較小的空間換取較大的操作成本
- time-space trad-off(時空折中)指的是對一結構而言,兩者成反比,更好的空間就會獲得較差的時間(運行速度慢)
- Multi-Level page table 相較 Linear page table 複雜很多,無論是 hardware還是os來處理TLB miss的查找page動作
詳細的Multi-level page table
- 現在假設我們有16KB的address space包含64個page,可以很簡單的計算出他的資訊
- 使用VPN的前四位當作page directory indexed(PDIndex),有了PDIndex就可以找到page directory entry address (PDE addr)
- In this example have 256 entries, spread across 16 pages

- 假設該PDE address的page directory被標記為有效的話,使用後VPN的後四位當作page table indexed(PTIndex),目的是為了從page directory 中找到指向的page table並獲取其中的page table entry(PTE)
- 這個PTIndex可以用來從page table中找到page table entry Address(PTEAddr)

超過兩級
- 現在假設有一個30KB的virtual address space和一個512Byte的page(一樣先計算可用訓息)
- 因為page的大小為512Byte且PTE大小為4MB,因此可以計算出Offset(相當這一個page table entry中可以放入多少page)
- 經過計算一個page table可以容納128個page
- 因此將VPN的最低7位元當作PTE Indexed (目的是讓page table知道該指向哪一個page table entry)

- 現在可以注意到還有14個位元留給page directory,假設我們將它看作page的話,offset沒辦法指向所有page
- 因此這時候將這14位進行切割,並讓他們當成指向其他page directory的index

-
VPN的前7位(PD index 0)用於fetch the page directory entry from the top-level page directory
-
如果valid的話,可以通過組合
- top-level Page directory entry(PDE)的physical frame number(PFN)
- VPN後7位元(PD index 1) 來查閱 second-level PDE
-
假設second-level PDE有效,thee PTE address can be formed(形成) by using the page-table index combined with the address from the second-level PDE
The Translation Process: Remember the TLB
- hardware會先檢查TLB,如果TLB hit的話physical address 可以直接獲得,而不用重新訪問page table
- 只有當TLB miss的時候,hardware 才需要執行完整的 multi-level 查詢 (兩次額外的memory access)
VPN = (VirtualAddress & VPN_MASK) >> SHIFT
(Success, TlbEntry) = TLB_Lookup(VPN)
if (Success == True) // TLB Hit
if (CanAccess(TlbEntry.ProtectBits) == True)
Offset = VirtualAddress & OFFSET_MASK
PhysAddr = (TlbEntry.PFN << SHIFT) | Offset
Register = AccessMemory(PhysAddr)
else
RaiseException(PROTECTION_FAULT)
else // TLB Miss
// first, get page directory entry
PDIndex = (VPN & PD_MASK) >> PD_SHIFT
PDEAddr = PDBR + (PDIndex * sizeof(PDE))
PDE = AccessMemory(PDEAddr)
if (PDE.Valid == False)
RaiseException(SEGMENTATION_FAULT)
else
// PDE is valid: now fetch PTE from page table
PTIndex = (VPN & PT_MASK) >> PT_SHIFT
PTEAddr = (PDE.PFN<<SHIFT) + (PTIndex*sizeof(PTE))
PTE = AccessMemory(PTEAddr)
if (PTE.Valid == False)
RaiseException(SEGMENTATION_FAULT)
else if (CanAccess(PTE.ProtectBits) == False)
RaiseException(PROTECTION_FAULT)
else
TLB_Insert(VPN, PTE.PFN, PTE.ProtectBits)
RetryInstruction()Swapping: Mechanisms
- 現在假設的都是address space 非常小能直接放入physical memory,為了支持更大的address space需要在memory hierarchy上增加一層
- 儲存結構變為大而慢的disk在底層

Why Need Bigger address space
- 有了巨大的address space,不用擔心是否有足夠空間儲存
- os為concurrency提供巨大address space 的 illusion
- 因此易用性和concurrency都是現代virtual memory system 會做的事情
Swap Space
-
將memory中的page交換到swap space中,並在需要的時候swap 回去(os需要寄主給定page的disk address)
- swap space大小決定了某時刻能使用的最大memory page數
-
由此圖片可以很簡單看出哪些process沒被執行(在swap space上),且可以發現
- swap space不會區分stack,code或是heap等,而是全部放一起

- 為了允許page被交換到disk,因此需要新增present bit在page table entry上
| present bit | 意義 |
|---|---|
| 1 | 代表該page 在 physical memory 中,並且所有內容都在進行 |
| 0 | 代表page不在memory中,而是在disk |
- 假設訪問不在physical memory上的page會觸發page fault,會由os專門處理(page-fault handler)
page-fault
- os該如何知道假設發生page-fault的page在哪裡(因為在page-fault handler的時候會將錯誤的page從disk swap 回 memory)
- os可以用PTE(page table entry)的位來儲存像page的PFN(page frame number)數據
演示如何查找到發生問題的page
- 當os接收到page-fault的錯誤時,會在PTE中查找address,並將request發給disk,再將page讀取到memory中
- 當DISK完成I/O之後,os更新page table將page的標記改為存在(存在在memory中)
- 更新PTE的PFN已紀錄新獲取page的memory address
- 重試instruction
PFN = FindFreePhysicalPage()
if (PFN == -1) // no free page found
PFN = EvictPage() // replacement algorithm
DiskRead(PTE.DiskAddr, PFN) // sleep (wait for I/O)
PTE.present = True // update page table:
PTE.PFN = PFN // (present/translation)
RetryInstruction() // retry instruction- 此時發生TLB Miss,但因為此時的page已經在memory中,因此更新TLB
- 重試instruction
- TLB hit,找到translation address並從中獲取所需的data或instruction
-
IO運行時process將會處於block狀態,因此當page-fault正常handle時,os會去運行其他能夠running的process
- 利用一個process進行IO(page-fault)時執行其他process稱為overlap
-
底下程式碼已經先將information從DISK swap 到 memory
VPN = (VirtualAddress & VPN_MASK) >> SHIFT(Success, TlbEntry) = TLB_Lookup(VPN)
if (Success == True) // TLB Hit
if (CanAccess(TlbEntry.ProtectBits) == True)
Offset = VirtualAddress & OFFSET_MASK
PhysAddr = (TlbEntry.PFN << SHIFT) | Offset
Register = AccessMemory(PhysAddr)
else
RaiseException(PROTECTION_FAULT)
else // TLB Miss
PTEAddr = PTBR + (VPN * sizeof(PTE))
PTE = AccessMemory(PTEAddr)
if (PTE.Valid == False)
RaiseException(SEGMENTATION_FAULT)
else
if (CanAccess(PTE.ProtectBits) == False)
RaiseException(PROTECTION_FAULT)
else if (PTE.Present == True)
// assuming hardware-managed TLB
TLB_Insert(VPN, PTE.PFN, PTE.ProtectBits)
RetryInstruction()
else if (PTE.Present == False)
RaiseException(PAGE_FAULT)- 可以注意到TLB miss發生的3種情況
- 該page present bit為1且valid
- TLB可以簡單從PTE中獲取PFN然後重試
- 該page present bit為0但valid
- 需要從Disk中拿回並存到memory
- 訪問的是 unvalid
- PTE其他位都不重要了,並且hardware捕獲這個非法access,os trap handler可能將kill process
Why not use hardware
- 從TLB知道hardware designer不信任os所做的事情,那為什麼會讓os進行page-fault的handle?原因如下
- page fault導致disk操作很慢,即使os需要花費大量時間/instruction來處理,但相較於disk開銷還是很小
- 為了處理page-fault,hardware必須了解swap space和其他細節
- 因此由於性能和難易度的關係,os來處理page-fault也是hardware designer認可的事情
When Replacements Really Occur
- OS並不會等到沒有空間了才進行swap(踢出page為其他page騰出空間),而是會預留一小塊free memory
- 為了保證有少量的free memory,OS會設定High Watermark (HW)和Low Watermark (LW)來幫助決定何時清除page
- os發現可用的page少於LW
- 後台負責釋放memory的thread開始運行
- 這個thread也被稱為swap daemon或page daemon
- 當os發現可用的page大於HW,後台thread進入休眠
- 為了配合後台的page thread,控制disk交換到memory的algorithm需要新增 page,而不是直接替換
- 如果沒有free page會通知後台page daemon來釋放page直到釋放到一定數目,再喚醒原先進行swap的thread進行swap
Swapping: Policies
- 今天在有限的memory中,os必須要能夠paging out一些page以避免memory pressure,而os要evict哪個page(或哪些page)封裝在replacement policy中
Cache management
- 為了要橫量hardware緩存而設計了一個專門的指標: AMAT(Average Memory Access Time)來計算program的平均memory access time
- 假設現在我們的hit rate為 90%, miss rate為 10%,每次訪問 memory成本為100ns,訪問Disk成本為10ms
- 此時假設我們命中率為99.9%()的話AMAT會快大約100倍,而當Hit rate為100%時會非常接近訪問memory花費的成本
The Optimal Replacement Policy
- 最佳替換策略的核心思想很簡單: evict 最晚才會再次訪問的page

- 假設現在cahce只能緩存3個page
- 前三次訪問都cache miss(這種miss也被稱為cold-start miss or compulsory miss)
- 再次訪問page0和page1都cache hit
- 這時新訪問了page3時就必須將其中一個page evict
- 由於可以發現page2會是相較之下最晚被再次訪問
- 踢掉page2然後將page3存進緩存中
- 這時可以計算緩存命中率: 有6次的Cache hit和5次的Cache miss
- 假設去除cold-start cache再次計算(忽略每一個page 第一次的access),因此可以將圖表轉換成
| Access | Hit/Miss? |
|---|---|
| 0 | Hit |
| 1 | Hit |
| 0 | Hit |
| 3 | Hit |
| 1 | Hit |
| 2 | Miss |
| 1 | Hit |
- 此時再重新計算Hit rate
- 不過The Optimal Replacement Policy建立在已知未來的情況,而未來是無法確定的,因此沒辦法透過os實現這種算法
FIFO
- 就像Queue一樣,假設現在memory已經滿了,但又有新的cache要插入,將最先被放入的給evict

Random
- 當memory滿的時候隨機選擇一個page將他evict,具有和FIFO一樣實現簡單的屬性

LRU
- 藉由將歷史訊息當作訪問頻率,如果一個page被訪問多次就不該被evict,並且這個訪問更看重recency,越接近需要evic時被訪問的page,再次訪問的機率更大
- 像LRU/LFU這種依照局部當全局來設計的策略便是局部性原則(principle of locality)

- 但實現LRU的代價非常昂貴,因此引發新的問題: 是否真的需要找到最舊的page替換