File system
File system in operating systems
IO
System Architecture
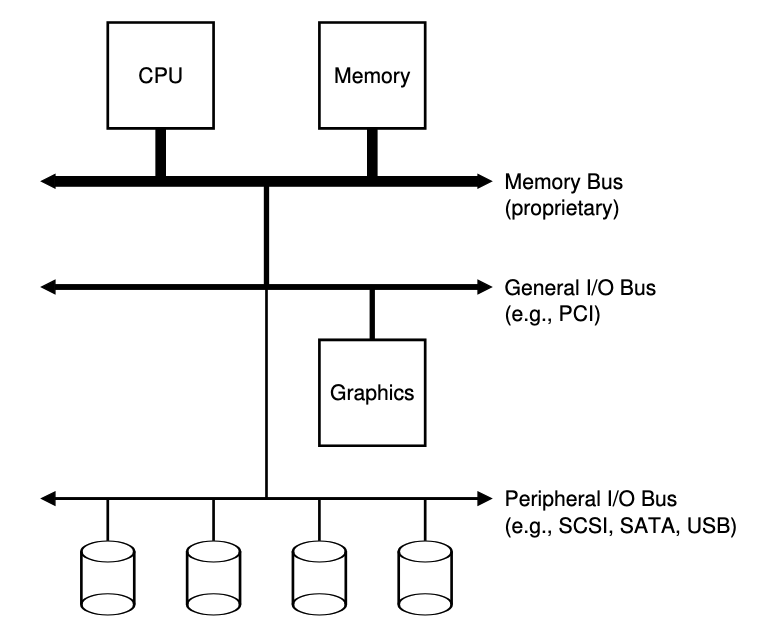
- 之所以有這樣連接IO和其他設備的原因是因為通常高性能的memory沒有足夠多的空間連接太多設備,且線的成本也相對較高
- 因此系統設計採用了分層的方式,將disk和其他低速設備連在外面,優點之一是可以連接大量設備
A Canonical Device
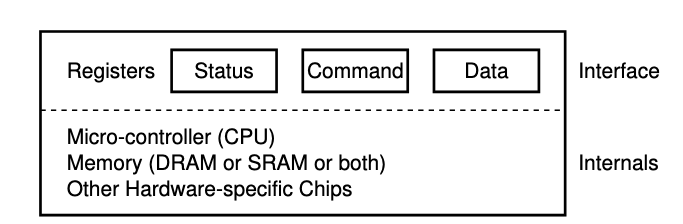
- interface的部分是為了讓系統軟體控制操作,因此所有設備都有自己的interface和交互協議
- internal structure 負責實現設備展示給系統的abstract interface
Lowering CPU Overhead With Interrupts
- 因為中斷的關係,系統不再需要使用輪詢的方式,而是發生中斷時讓CPU執行預先定義的ISR,或更簡單的interrupt handler
- 由於中斷的引入,當發生IO中斷的時後,原先的CPU不再只有空等待,而是可以做其他事情,直到觸發IO的中斷返回
- 因此並不是任何時候都會採用中斷,尤其遇到高性能設備(處理請求非常快),或是網路(假設每一個封包都會發生中斷,會觸發os的livelock,即不斷處理中斷而無法處理用戶layer請求)
- 更多時候會採用hybird策略,先輪詢一段時間後,再交給中斷
- 或使用合併(coalescing)的方式,將多個中斷合併成一個,當然因為等待時間長而增加請求的延遲,但這是os對中斷的一種折中方式
DMA
-
使用編程的IO將一大塊數據傳給設備,圖中會依賴CPU進行繁瑣操作

-
從圖上來看不難發現, process 1 需要進行IO操作,而這期間還需要先讓CPU進行COPY到IO設備上才可以,需要等待到IO設備開始運作,CPU才可以繼續運行其他process
-
解決方式使用DMA(Direct Memory Access),DMA為了能夠將數據傳送給設備,因此os會透過程式告訴DMA引擎數據在memory中的位址,要拷貝的大小以及要拷貝過去的設備,接下來就可以全權交給DMA處理
- 當DMA完成後,DMA Controller會拋出一個interrupt來告訴os完成數據傳輸
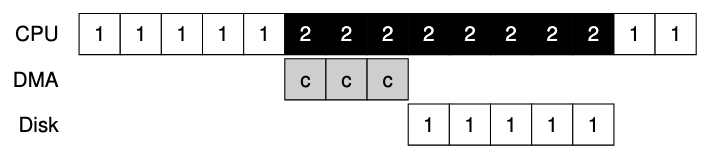
- 當DMA完成後,DMA Controller會拋出一個interrupt來告訴os完成數據傳輸
Methods Of Device Interaction
- 使用指令的方式讓io間進行交互,這些指令通常是privileged,因此會產生危險性
- 使用memory-mapped IO,透過這種方式,hardware將設備register當作memory address提供,當需要訪問時,os讀取或寫入到該memory address,然後hardware會將R/W轉移到設備上,而非physical address
HardDisk Driver
interface
- 現在的harddisk都是由512byte組成,並且有0~n-1的編號,這些編號也相當於是address space
- 唯一保證的是單個512byte寫入為atomic,因此假設寫入的數據大於512byte並且剛好斷電,則會變成不完整寫入(torn write)
- 通常可以假設靠近的block訪問速度會比相遠的block快
A Simple Disk Drive
- 下圖為一個簡單disk範例圖示,其中只有12個扇區(sectors),每個扇區512byte,並且用0~11的編號
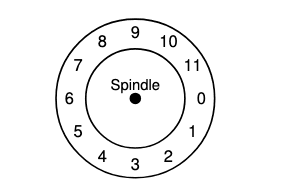
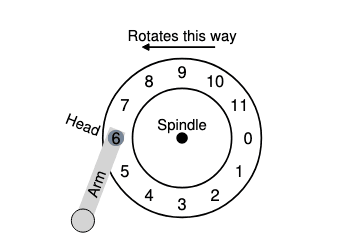
Single-track Latency: The Rotational Delay
- 簡單的disk中,disk不需要做太多得工作,主要是等待期忘的sectors旋轉到disk head下,而這便是所謂的rotational delay
- 如果完整旋轉延遲是,disk必然產生大約為的旋轉延遲,已等待0來到讀/寫disk head下(如果從6開始)
Multiple Tracks: Se
- 這張圖表面有3條tracks,最內圈的包含sectors 24
35,最外面則是011
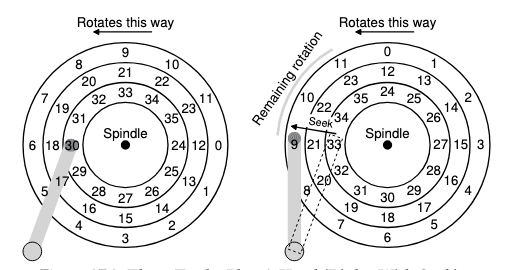
-
假設我們現在要讀取sector 11
- driver首先將disk arm移動到正確的sector上,這個過程稱為seek(seek 和 rotation為最昂貴的操作之一)
- 開始進行seek的動作,會分為
- disk arm加速階段
- disk arm全速移動而慣性滑動
- disk arm在正確的track停下
- seek之後就會在正確的track上
- 等待rotational delay,直到sector 11來到disk head下
- 當sector 11來到disk head下,就可以開始最後的IO階段,這階段也被稱為transfer,數據從表面讀取或寫入表面
-
完整IO時間圖分成
- seek time
- rotational delay
- transfer time
Multiple track的一些細節
- driver會採用某種形式的track skew,以確保跨越 track boundaries時也可以順序讀取服務
- sector也會偏斜,避免遇到切換track時,原本的sector剛剛被經過,而需要等待完整的rotation delay
- 外圈track具有更多的sectors,這些track通常被稱為multi-zoned disk driver
- disk driver都會有一個緩存,也稱為track buffer,當disk讀取sector時,driver決定讀取該track上的所有sector並緩存
- 在寫入時應該要將data放入memory(write back,有時也稱為immediate reporting)還是寫入實際disk再回報(write through),write back 緩存有時候會比driver更快但更危險
IO time
- IO時間可以分為3個主要部分
- 通常比較driver用IO的速率
- 計算平均seek時間
- 由此可知平均seek時間為完整seek時間的
Disk scheduling
- 每個任務的時間都是不確定的,因此對於disk scheduling可以用猜測的方式知道會花費多長時間,通過估計請求的查找和可能的rotation delay
- Disk scheduling會遵守SJF(Shortest Job First)原則,即優先處理最短的請求,這樣可以減少平均等待時間
SSTF(Shortest Seek Time First)
- SSTF是一種基於當前磁頭位置的調度算法,每次選擇距離當前磁頭位置最近的請求進行處理
- 優點是能夠有效減少平均尋道時間,特別是在請求集中在某些區域的情況下
- 缺點之一是可能導致某些請求長時間得不到服務,即產生飢餓現象
- 另外一個問題是os無法看到driver的幾何結構,而制止會看到一系列的block
- 使用NBF(Nearest-Block-Frist)然後用最近block的address來調度請求
SCAN
- 如果請求的block所屬的track已經被掃過了,就不會立即處理,而是排隊等待下一次掃描
- F-SCAN,會先將掃描的請求放入qeueue中,已便稍後處理,利用這種方法避免遠距離的reqest starvation,延遲了遲到請求的服務(此服務比之前的服務和disk head的距離更近)
- C-SCAN(Circular SCAN),會將磁頭移動到最外圈,然後從最外圈開始掃描,這樣可以確保所有請求都能夠被處理,並且避免了飢餓現象
SCAN或是SSTF都沒有遵守SJF原則,因為接忽視了旋轉
SPTF(Shortest Positioning Time First)
- 有時也被稱為Shortest Access Time First(SATF)
- SPTF會考慮到磁頭的當前位置和請求的距離,選擇最短的請求進行處理(簡單來說會視情況而定LIVNY定律)
- 現代的drive中,查找和旋轉大致相同,因此SPTF可以提高性能,但在os中實現較為困難(因為os並不知道track bound在哪,也不知道disk head當前位置),因此SPTF通常在drive內部執行
IO merging
- 假設讀取的block為33,8,34.這種情況下scheduler應該將block 33,34合併成一個request,從而減少開銷
- disk發出IO前系統應該要等待一段時間,即所謂的non-work-conserving方法,透過等待,更好的request可能會到達disk從而提高效率
RAID(Redundant Array of Inexpensive Disks)
- 外部來看RAID是一個disk,一組可以RW的block
- 內部來看RAID非常像一個os,專門管理一組disk,其中內部含有多個disk,memory(包含持久性(ROM)和非持久性(RAM)),以及一個或多個CPU來管理系統
- RAID能夠並行使用都個disk增加性能,並且能夠容忍一個disk的故障(在多個disk上並且沒有使用RAID技術,會使數據容易受到一個disk丟失影響)
RAID Interace
- RAID將自己展現為線性的block,這些block都可以由file system或其他client進行RW
- 在高層面上RAID是一個專業的os,有cpu,memory和disk然後他不是運行應用程式,而是運行RAID專們的操作軟體
故障模型
- RAID必須要檢測到這些磁盤故障並且恢復
1. 停止(fail-stop)故障模型
- disk可以有兩種狀態,分別是工作狀態*和故障狀態**
- 工作狀態
- 故障狀態,並且我們認定為丟失
- 停止模型的關鍵檢測在於假定,當disk發生故障時,在RAID陣列中有控制硬體或軟體可以立即檢測到何時發生故障
- 因此不必擔心更複雜的無聲故障(如磁盤損壞),或是disk無法訪問單個block(扇區錯誤)
評估RAID
- 容量(capacity)
- 給定N個磁盤情況,RAID的client容量有多少(理想情況為N).如果有一個系統保存每個block的兩個副本,獲得的容量
- 可靠性(reliability)
- RAID系統能夠容忍多少個磁盤故障而不會丟失數據
- 性能(performance)
- 性能比較難評估,因為取決於disk array提供的工作負載,因此只考慮典型的工作負載
- RAID 0級(條帶化)
- RAID 1級(鏡像)
- RAID 4/5級(基於奇偶效驗的攏於)
- 性能比較難評估,因為取決於disk array提供的工作負載,因此只考慮典型的工作負載
詳細評估性能
- 單請求延遲,了繳單個IO請求對RAID滿意度,主要用來揭示單個logic IO操作期間能存在多少並行性
- RAID穩態吞吐量,即為並發請求的總帶寬
- 工作服載只考慮
- 順序(sequential)一個請求訪問1MB數據,始於block(B),終于block(B+1MB)就為認為是連續
- disk以最高速行駛,花費很少的時間seek並等待rotation,大部分時間都會在transport上
- 隨機(random)在logic address 10的地方訪問4KB,然後在400的時候訪問.就被認為是隨機
- 大部分時間花在seek和等待rotation,花在transport上時間較少
開始分析
- 使用 代表順序傳輸數據
- 使用 代表隨機傳輸數據
RAID映射問題
- 假設A為邏輯地址A,RAID可以使用兩個簡單的公式輕鬆計算要訪問的磁盤和偏移量
RAID 0級: striping
- striping可以作為性能和容量上限,在系統上的disk上將block進行striping
- 從穩態吞吐的角度,我們期望獲得系統的全部帶寬
| disk0 | disk1 | disk2 | disk3 |
|---|---|---|---|
| 0 | 1 | 2 | 3 |
| 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 |
- 以輪轉方式將disk array的block分布在disk上,目的是在對array連續block進行request時,從array中獲取最大的並行性
- 將同一row的block稱為strip,因此0,1,2,3在相同strip上
Chunk Size
- 大小較小的chunk意外著許多文件將跨多個disk進行striping,從而增加了對單個file的rw並行性
- 但是定位時間也會增加,因為整個request的請求定位時間由所有drive上請求的最大定位時間決定
- 較大的chunk大小減少了文件內的並行性,因此依靠多個並發請求來實現高吞吐量
RAID 1級 (Mirror)
- 在striping的基礎上為每一個block生成多個副本,並且放在一個單獨的disk上以容忍disk故障
| disk0 | disk1 | disk2 | disk3 |
|---|---|---|---|
| 0 | 0 | 1 | 1 |
| 2 | 2 | 3 | 3 |
| 4 | 4 | 5 | 5 |
| 6 | 6 | 7 | 7 |
- 在讀取時可以從任一副本中讀取,寫入時則必須保證副本內容皆一致(可以並行寫入)
RAID 1級分析
- 容量(capacity)
- 對於N個disk,Mirror可用容量為
- 可靠性(reliability)
- 鏡像級別為2時(每個block都有一個自己的副本),最多可以容忍 個disk故障
- 性能(performance)
- 需要兩次物理寫入,但由於並行的關係,會和一次物理寫入大致相同
- 然而因為logic寫入必須等待物理寫入完成,因此遭到兩個請求中最差的seek和rotation delay,平均而言消耗時間略高於比單個寫入
- 因為要同時寫入副本,因此帶寬為 ,原因是不會同時處理所有請求
- 隨機寫入 ,獲得一半可用帶寬實際上相當不錯,因為許多小請求的帶寬只能達到我們看到striping的一半
- 需要兩次物理寫入,但由於並行的關係,會和一次物理寫入大致相同
RAID 4級parity
- 用時間換取空間,藉由奇偶效驗的方式試圖使用較少的容量,克服由mirror付出的巨大空間損失
| disk0 | disk1 | disk2 | disk3 | disk4 |
|---|---|---|---|---|
| 0 | 1 | 2 | 3 | P0 |
| 4 | 5 | 6 | 7 | P1 |
| 8 | 9 | 10 | 11 | P2 |
| 12 | 13 | 14 | 15 | P3 |
- 使用XOR來承受條帶中任何一block的損失
| C0 | C1 | C2 | C3 | P |
|---|---|---|---|---|
| 0 | 0 | 1 | 1 | XOR(0,0,1,1)=0 |
| 0 | 1 | 0 | 0 | XOR(0,1,0,0)=1 |
- 只需要讀取該row中的所有值(包含XOR的奇偶效驗位)並且重構(reconstruct)正確答案,就可以利用奇偶效驗訊息從故障中回覆
RAID 4級分析
- 使用一個disk作為他所保護的每組disk奇偶效驗的訊息
- 穩定吞吐量可以使用奇偶效驗disk以外的其他Disk完成,因此提供
- 寫入方面的話,RAID 4級使用full-stripe write的方式寫入
- 假設要寫入block 0,1,2,3,先通過讀取的方式計算P0的新值(XOR(0,1,2,3)),接著就可以並行的方式寫入對應的請求的Block
- 順序寫入的有效帶寬即為
- 假設要寫入block 0,1,2,3,先通過讀取的方式計算P0的新值(XOR(0,1,2,3)),接著就可以並行的方式寫入對應的請求的Block
- 隨機讀取的話帶寬為,因為隨機讀取將分布在系統的數據Disk上,奇偶效驗不會參與到
| disk0 | disk1 | disk2 | disk3 | disk4 |
|---|---|---|---|---|
| 0 | 1 | 2 | 3 | P0 |
| 4 | 5 | 6 | 7 | P1 |
- 現在的情況是,假設我們需要寫Block1,該如何正確有效的更新P0(奇偶效驗值)
- 加法效驗(additive parity)
- 並行讀取其他Block的值,然後使用XOR的方式計算新的P0,新數據block和新奇偶效驗值也可以並行寫入
- 問題是當Disk數量變化,在較大的RAID中需要讀取大量的Block導致性能下降
- 減法效驗(subtractive parity)
- 假設目前block和奇偶效驗值為
| C0 | C1 | C2 | C3 | P |
|---|---|---|---|---|
| 0 | 0 | 1 | 1 | XOR(0,0,1,1)=0 |
- 流程如下
- 假設我們需要使用新值來覆蓋C2
C_old = C2
C_new = read(C2_new)
P_old = P0
if C_old == C_new then
P_new = P_old
else
P_new = (C_old XOR C_new) XOR P_old
end- 隨機寫入
- 假設同時獲得Block 1和 Block 4的寫入請求,那必須要讀取P0和P1的值
- 儘管可以並行的讀取Block 1和Block 4,奇偶效驗Disk沒有辦法實現任何並行(因為P0和P1都在Disk4上)
- 這也被稱為基於奇偶效驗的RAID小寫入問題(small-write problem),其中可以計算奇偶效驗Disk在這兩個IO(每個邏輯IO上的RW)上的性能來計算隨機寫入性能
- RAID中小寫入性能非常糟糕,並且添加Disk也不會改善(原因是主要都是奇偶效驗Disk的性能瓶頸)為
| disk0 | disk1 | disk2 | disk3 | disk4 |
|---|---|---|---|---|
| 0 | 1 | 2 | 3 | P0 |
| 4 | 5 | 6 | 7 | P1 |
RAID 5級 旋轉奇偶效驗
- RAID 5級和4集基本上工作原理完全相同,不同的是將奇偶效驗塊跨driver的旋轉
| disk0 | disk1 | disk2 | disk3 | disk4 |
|---|---|---|---|---|
| 0 | 1 | 2 | 3 | P0 |
| 5 | 6 | 7 | P1 | 4 |
| 10 | 1 | P2 | 8 | 9 |
| 15 | P3 | 12 | 13 | 14 |
RAID 5級分析
- 性能好是因支持並行(相當於操作Disk)
- 除了隨機寫入以外,其他和RAID 4級基本上一樣
- 寫入Block 1和10的話,相當於
- 寫入Block 1轉變成對Disk 1和 Disk 4的請求(block 1和其奇偶效驗)
- 寫入Block 10轉變成對Disk 0和 Disk 2的請求(block 10和其奇偶效驗)
- 因此現在寫入的Disk都不一樣,因此可以並行寫入,而提高性能
- 因此帶寬為,其中4被損失為每個RAID-5寫入產生的總IO操作
- 有時候使用RAID-4還是比RAID-5,主要是構建簡單,且功能差不多,並且當系統知道自己只執行大寫入操作時(這樣避免了小寫入問題)
RAID 總結
| RAID-0 | RAID-1 | RAID-4 | RAID-5 | |
|---|---|---|---|---|
| Capacity | ||||
| Reliability | 0 | 1 (for sure) or (if lucky) | 1 | 1 |
| Throughput | ||||
| Sequential Read | ||||
| Sequential Write | ||||
| Random Read | ||||
| Rando Write | ||||
| Latency | ||||
| Read | ||||
| Write |
- 對性能不要求的話,strip顯然是最好的
- 想要隨機IO的性能和可靠性,Mirror是最好的,但代價是容量下降
- 容量和可靠性是主要目標,選擇RAID-5,付出的代價是小寫入的性能
- 按順序執行IO操作並且希望容量最大化,選擇RAID-5也是最有意義的
Files and Directories
- 持久儲存(presistent storage)用來永久儲存訊息,如hard disk driver或solid-state storage deviceㄡ.持久儲存設備和memory不同,memory斷電時會丟失內容
File and Diretory
- 儲存虛擬化形成兩個關鍵的Abstraic
- 文件 File
- 文件通常都有一個與之關聯的inode number,並且沒辦法被使用者知道
- os並不清楚文件的結構,而是只在乎資料是否將數據永久保存在Disk上,並且當查找時能將結果返回
- 目錄 Directory
- 目錄也具備inode number但內容非常具體,為一個(用戶可讀名字, low-level name) pair 的list,
- i.e. if the low-level name is 10 for file and the name for user is foo, it will present like ("foo","10") in directory
- 目錄中的每個條目都指向文件或其他目錄,用戶可以構建directory tree or directory hierarchy來在該tree下儲存file和directory
Creating File
- open 的返回值為file description,其為一個int並且process為private
int fd = open("foo", O_CREAT|O_WRONLY|O_TRUNC);Read/Write File
- 使用cat來將測試rw file
- 之所以open返回的結果為3而不是1試印為正在運行的process打開了3個file
- stdin (process可以讀取以接收寫入)
- stdout(process可以寫入以便將訊息印在screen)
- stderr(process可以寫入錯誤訊息)
prompt> strace cat foo
...
open("foo", O_RDONLY|O_LARGEFILE) = 3
read(3, "hello\n", 4096) = 6
write(1, "hello\n", 6) = 6
hello
read(3, "", 4096) = 0
close(3) = 0
...
prompt>- 使用write寫入時系統通常會先將內容儲存在buffer中,並等待一段時間後寫入
fsyne
- 使用fsyne能夠讓file system強制寫入所有的dirty 數據,一但所有寫入完成變返回
int fd = open("foo",O_CREAT | O_WRONLY | O_TRUNC);
assert(fd > -1);
int rc = write(fd,buffer,size);
assert(rc == size);
rc = fsync(fd);
assert(rc == 0);File Rename
- rename操作通常是一個atomic調用,不會因為系統崩潰而導致發生中間情況(失效為舊名稱,成功為新名稱)
- 假設現在要在舊名成為
foo.txt內新增一行,實際操作會類似如下
int fd = open("foo.txt.tmp",O_WRONLY | O_CREAT | O_TRUNC);
write(fd,buffer,size);
fsync(fd);
close(fd);
rename("foo.txt.tmp","foo.txt");硬連接 link and Unlink
- 使用ln的方式來連接,link只是在要創建連接的目錄中創建一個名稱,並將其指向原有文件的相同inode號,該文件不以任何方式複製
- 假設我們先調用Unlink來解除兩file間的連接,再調用rm來嘗試刪除file
rm file # remove file
cat file2 # hello- 會發現file2內還是file的內容,儘管我們已經unlink並且刪除file
- 因為調用unlink的時候刪除可讀名稱和給定inode間的連接,並減少引用計數,只有當引用計數到0時,file system才會釋放inode和相關data block,從而達到真正的刪除文件
- 因此只有rm而沒有unlink的話不會真的刪除block
軟連接 symbolic link
- 硬連接有以下局限
- 不能創建目錄的硬連接(避免建立cycle)
- 硬連接到其他disk分區中的文件(因為inode number在特定文件系統中是唯一的)
- 使用
ln -s來建立軟連接,不同的地方是會將連接指向文件的路徑名作為連接文件的數據,因此連接到的路徑名長度和連接文件的大小成正比- 但也因為連接的方式為路徑名,因此有可能造成 dangling reference,即為指向的路徑名是空的
掛載
- Mount在很多地方都會看到,像是實現最簡Docker container所呈現的方式也是調用Mount
func child() {
cg()
syscall.Sethostname([]byte("container"))
// chroot must need /bin and other
must(syscall.Chroot("/usr/"))
syscall.Chdir("/")
must(syscall.Mount("proc", "proc", "proc", 0, ""))
// ...
syscall.Unmount("/proc", 0)
}Permission Bits And Access Control Lists
- 因為file時常會在不同process間共享,因此有更完整的機制支援文件間的共享
- UNIX permission bits
prompt> ls -l foo.txt
-rw-r--r-- 1 remzi wheel 0 Aug 24 16:29 foo.txt-
第二行中呈現了3種不同使用者權限範圍的區塊
- owner 為 rw
- what someone in a group can do to the file (這邊的group為linux使用者群組)
- anyone (sometimes referred to as other) can do
-
使用chmod來修改檔案權限bits
chmod 600 foo.txt-
這指令將以下權限變為
- owner權限為設定6,其中代表為(可讀位元4)和(可寫位元2)
- group和other則皆為0(沒有權限)
-
因此檔案permission bits會呈現
-rw------- -
在一些分散式的file system存在ACL(access control list)對於每個目錄
- 這個list裡面可以讓使用者創建一個特別的內容,目的是讓file system知道 who can read and cannot read the file
Implement File systems
- we will introduce a simple file system which called VSFS(Very Simple File System)
The way to think
The problem
- data structure of the file system
- access Methods. How does it map the calls made by process
Overall Organization
-
文件系統必須記錄每個文件的訊息,該訊息為metadata的關鍵部分,記錄包含
- data block
- file size
- permission
- accress and modify time
- 為了儲存這些訊息,通常在Disk上保存了一個inode array,並且將以上資訊存入inode上
-
使用bitmap來記錄inode或是datablock是空閑還是被使用
- 一種用於data 區域(data bitmap)
- 一種用於inode區域(inode bitmap)
-
其中還有一塊超級block (super block) 用來存放特定file system的訊息,例如有多少inode和data block
|S|i|d|I|I|I|I|I| |D|D|D|D|D|D|D|D|
|-inodes--| |--data blocks--|File Organization: The Inode
- inode是index node的縮寫,這名稱是因為一開始將這些node放在一個數組,訪問特定inode時使用該array的index
-
要讀取inode number 32會進行以下步驟,從而讀取到正確的byte address
- filesystem 首先會計算node區域的offset(32 * inode size)
- 加上disk上的start address
-
計算inode快的frame address iaddr
設計inode
-
設計inode一種簡單的方式是在inode中有一個或多個直接指針(disk pointer)
- 最重要的決定是如何引用data block位址
-
多級索引
- 目的是為了支持更大的filesystem,常見的思路是在inode結構中引入indirect pointer,指向的不是用戶data block,而是point to the block which include more pointer, and point to user data block pre pointer
-
assume per block is 4KB , disk address is 4bytes, then it increase 1024 number of pointer, and file will increase to
-
在設計索引的時候使用不平衡術來指向文件block的multi-level index,假設block為4KB,pointer為4Byte,則可以容納超過4GB的file
- 這邊的第一個1024為間接block,1024的平方則為雙重間接block
-
不使用平衡樹的原因是,這種不平衡設計反應了大多數文件很小的現實,並且inode只是一個 data structure,任何可以儲存相關訊息並有效查詢的結構即可
Access Paths: Reading and Writing
open("/foo/bar",O_RDONLY);- 當發出一個open調用時,file system要先找到該文件的inode,從而獲取相關訊息,因此filesystem 必須traverse path name從而找到所需要的inode
- 根的inode number必須是眾所皆知的,在mount filesystem時,filesystem必須知道他是什麼
- 一但inode被讀入,filesystem可以在其中查找指向data block的pointer來獲得根目錄的內容
- traverse path name 直到找到所需的inode
- 在這範例中,filesyste讀取包含foo的inode及其目錄的data block,最後找到bar的inode
- open將bar的inode讀入memory,進行 permission check, 在每個process的打開文件表中,為這個process分配一個file description並返回user
- 當read發生時除非lseek被調用,否則從offset為0的地方開始讀取block,查閱inode來查找block address,並且更新最後訪問時間(在inode結構中),進一步更新file description 在memory打開文件表,更新offset以此類推
- 當文件被關閉時,file description會被釋放,但這是filesystem要做的事情,不會在Dik上發生
- write的時候file會allocate一個block,寫入操作不緊需要將數據寫入disk,還必須首先決定將哪個block分配給file,因此IO的量很大
- 讀取inode bit map
- one write into inode bit map another write into new inode for self
- write into directory structure (link the high-level name to inode number)
- read write directory for update
Cache and Buffering
- 大多數文件系統積極使用系統memory(DRAM)來緩存重要的Block
- 沒有緩存的情況下讀取長路徑名僅僅打開文件就需要執行上百次讀取
- 早期使用fiexd-size cache來保存常用的block
- 問題是這種static partitioning可能導致浪費,當系統根本不那麼多memory的情況
- 現代系統使用dynamic partitioning,具體來說os將virtual memory page和file system page集成到統一unified page cache,從而更靈活分配memory
- 第一次打開文件會產生很多IO流量來讀取目錄的inode和數據
- 但第二次打開會基本上會全部命中cache從而不需要IO
- 但因為寫入流量必須進入Disk才能實現持久化,因此cache沒辦法減少寫入流量,因此需要使用 write Buffering
- 透過延遲寫入(delaying write) 文件可以將一些更新編成一個batch放入一組較小的IO中
- 通過將一些write buffering在memory,系統可以schedule後續的IO從而提高性能
- 寫入可以通過delaying來完全避免
- e.g. 創建文件並將他刪除,則文件創建一個延遲寫入Disk可以完全avoid這無效的寫入
- 由於buffering會照成一段延遲時間,有些application為了避免過程中發生問題導致沒有順利寫入,會調用
fsync()使用繞過緩存的direct IO interface 或者 raw disk interface 來完全避免使用file system
Fast file system
problem
- unix file system 將 disk當作隨機存儲memory,因此文件記憶體可能會散佈在memory中的任何位置,當讀取inode後讀取文件的block時會導致昂貴的seek操作
- 更糟糕的是因為隨機存儲block的關係,導致整個系統碎片化(fragmented)因為空閑區域沒有妥善管理
- 另一個問題是原始block大小,較小的block可以避免內部碎片化,但會導致不斷訪問而性能下降
FFS
- FFS 將磁碟劃分為組(cylinder group), for example which disk have 10 cylinder groups
- the cylinder group is the most important to imporve efficency for ffs
- if we have two file we can put then into the cylinder group together and ffs will promise be fist and last to access these file and it provide the promise which can avoid the long time on disk seek when we access the file
_____________________________ |G0|G1|G2|G3|G4|G5|G6|G7|G8|G9| - for the group we need to record the inode number and data block is allocated in the cylinder group, to make sure we use the inode bitmap(ib) and data bitmap(db)
_________________________________ |S|ib|bd|inodes |data | - last inode and datablock like the simple file system,the cylinder group include the more datablock
Policy
- the rule we called it the same put together
- for the directory, we will find the cylinder group wich allocated is smaller than another and more free inode
- for the file, ffs do the two thing to comply with the rule
- put the file data block and inode from the same cylinder group
- put the all file which in the directory to the same cylinder group
Expect big file
- 將一定數量的塊分配給第一個塊組
- 將已經放在第一個快組中指向間接資料的塊分配給第二個塊組
- 重複第1,2步
for example
- ffs didn't have the Expect of bif file
|G0|G1|G2|G3|G4|G5|G6|G7|G8|G9|
|01|
|23|
|45|
|67|
|89|- ffs have the Expect of big file
|G0|G1|G2|G3|G4|G5|G6|G7|G8|G9|
|89| |67| |45| |23| |01|- 如果block大小足夠大的話,大部分的時間都會在傳輸而非在大塊間的尋道上
FFS的其他優勢
- for file system if the file size is 2KB use 4KB to transport is better than original but it will occur internal fragmentation
- FFS use sub-block to slove this problem
- 隨然第一種方法避免了internal fragmentation但因為sub-block大量的IO複製導致性能下降
- FFS 針對性能進行優化的磁碟佈局,將block交錯的放置,通過跳過塊的方式來確保下一塊經過磁頭時有足夠的時間發出請求
- FFS是最早允許長文件名的系統之一,使用符號連接的方式取代硬連接
Crash Consistency: FSCK and Journaling
- 文件系統一個重要的主要挑戰當發生power lose或是system crash的情況如何更新數據
崩潰場景
- Just the data block (Db) is written to disk
- Just the updated inode (I[v2]) is written to disk
- Just the updated bitmap (B[v2]) is written to disk
- The inode (I[v2]) and bitmap (B[v2]) are written to disk, but not data (Db)
- The inode (I[v2]) and the data block (Db) are written, but not the bitmap (B[v2])
- The bitmap (B[v2]) and data block (Db) are written, but not the inode (I[v2])