DDIA第一章
DDIA第一章學習筆記
Introduce
數據密集型
- 因為現今服務多為數據密集型(data-intensive)而非計算密集型(compute-intensive)
- 數據量,數據複雜性,數據變更速度為主要問題,CPU反而是其次
數據密集型組建
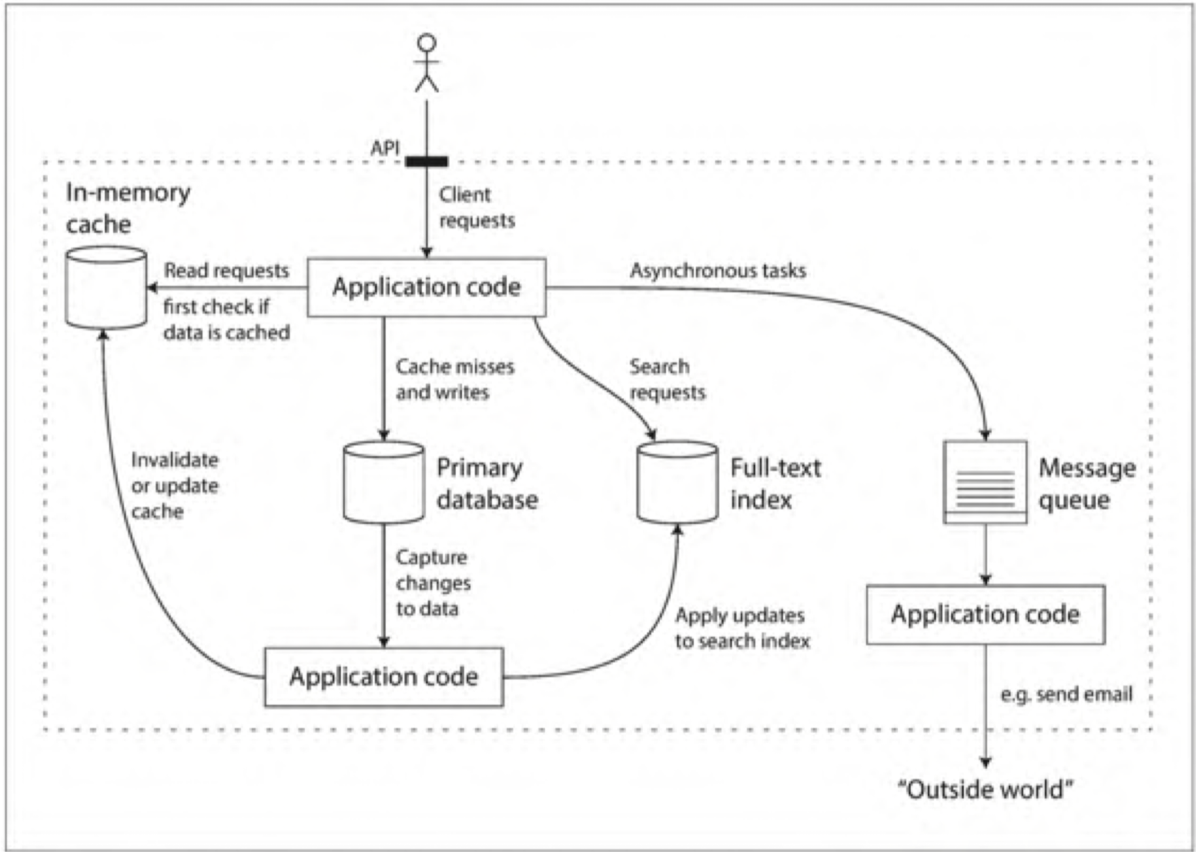
- Database
- 存儲技術
- Cache
- 記住開銷昂貴操作的結果,加快讀取速度
- Search indexes
- 允許使用關鍵字搜尋數據,各種方式對數據進行過濾
- stream processing
- 向其他process發送消息,進行異步處理
- batch processing
- 定期處理累積的大批量數據
數據系統思考
- 由於新的數據儲存工具和處理工具針對不統場景優化,因此類別間的界線變得越來越模糊
- 程序有著各種嚴格而廣泛的要求,單工具不足以滿足需求,因武將工作拆分成能被單個工作高效完成的任務
主要問題
- 可靠性(Reliavility)
- 系統在adversity中人可證工作(正確完成功能,並達到期望水準)
- adversity包含硬體故障,軟體故障,人為錯誤
- 可伸縮性(Scalability)
- 合理辦法對應系統增長
- 可維護性(Maintainability)
- 驗不同人的不同的life cycle中,高效的在系統上工作,使系統保持現有行為,並且適應新場景
可靠性
- 造成錯誤的原因為fault,能預料並應對fault為fault-tolerant或resilient
- 要注意的是fault不同於failure,fault定義為系統一部分偏離標準,failure則是系統停止服務
- 好的在fault-tolerant機制以防fault導致failure
fault-tolerant 系統
- 故意觸發來提高fault率是有意義的
- 故意引發fault來確保fault-tolerant機制不斷運行並接受考驗
因此比起prevent error 更傾向於‘fault-tolerant
各種錯誤介紹
- 硬體錯誤
- 增加硬體攏於度,現今只要能快速備份都不是毀滅性問題
- 軟體錯誤
- 只要能提供以下保證,那摩系統就可以在運行時不斷自檢,並在出現discrepancy時報警
- 仔細考慮系統中的
- 假設和交互
- 測試
- 隔離process
- 允許崩潰重啟
- 測量並監控行為
- 人為錯誤
- 沒辦法避免的...
如何讓系統便可靠
- 以最小化犯錯機會的方式設計系統
- 將最容易犯錯的地方與可能導致failure的地方decouple
- 在各階層進行徹底的測試,自動化測試適合用在少見的corner case
- 允許從人為錯誤中簡單快速地恢復
- 配置詳細和明確的監控,在工程學科只的是telemetry
- 良好的管理實踐與充分的培訓